
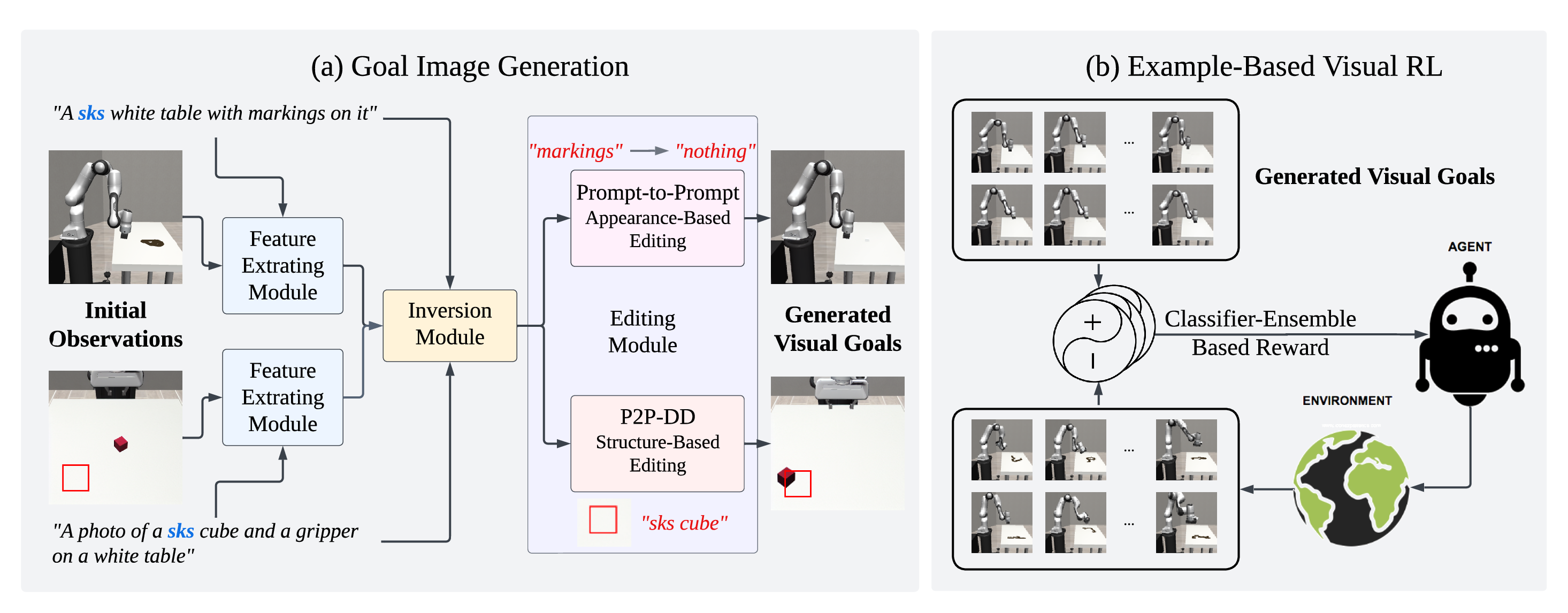
 LfVoid consists of two parts: (a) Goal image generation, where
we apply image editing on the initial observations according to different editing instructions to obtain
a visual goal dataset; (b) Example-Based Visual RL, where we perform reinforcement learning on the
generated dataset to achieve the desired goal image in various environments.
LfVoid consists of two parts: (a) Goal image generation, where
we apply image editing on the initial observations according to different editing instructions to obtain
a visual goal dataset; (b) Example-Based Visual RL, where we perform reinforcement learning on the
generated dataset to achieve the desired goal image in various environments.

Goal generation results of LfVoid on appearance-based editing. The Wipe task and LED task require changing the appearance of an object, such as the surface of a table and the color of a LED light.
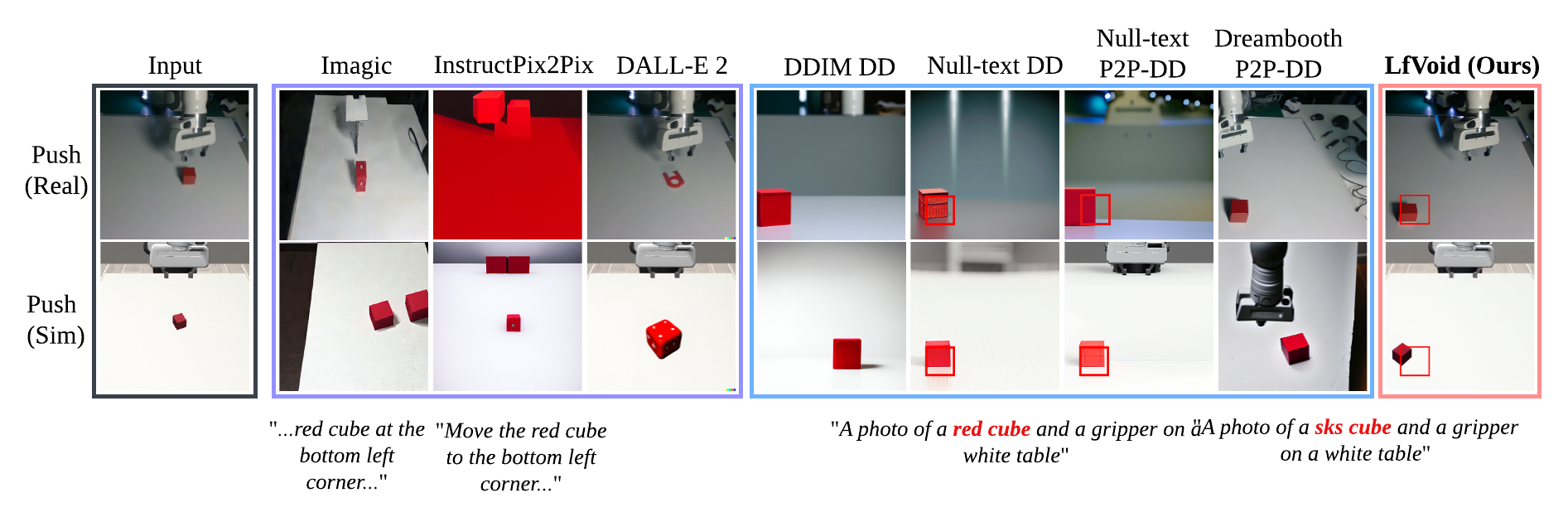
Goal generation results of LfVoid on structure-based editing. The Push task requires changing the structure of an image, such as relocating the red cube from the center of an image to the corner.

General editing results of LfVoid. We report the performance of LfVoid on general editing tasks and show that LfVoid can better perform localized edits and preserve the background of the original image.

Additional results of goal images generated by LfVoid.
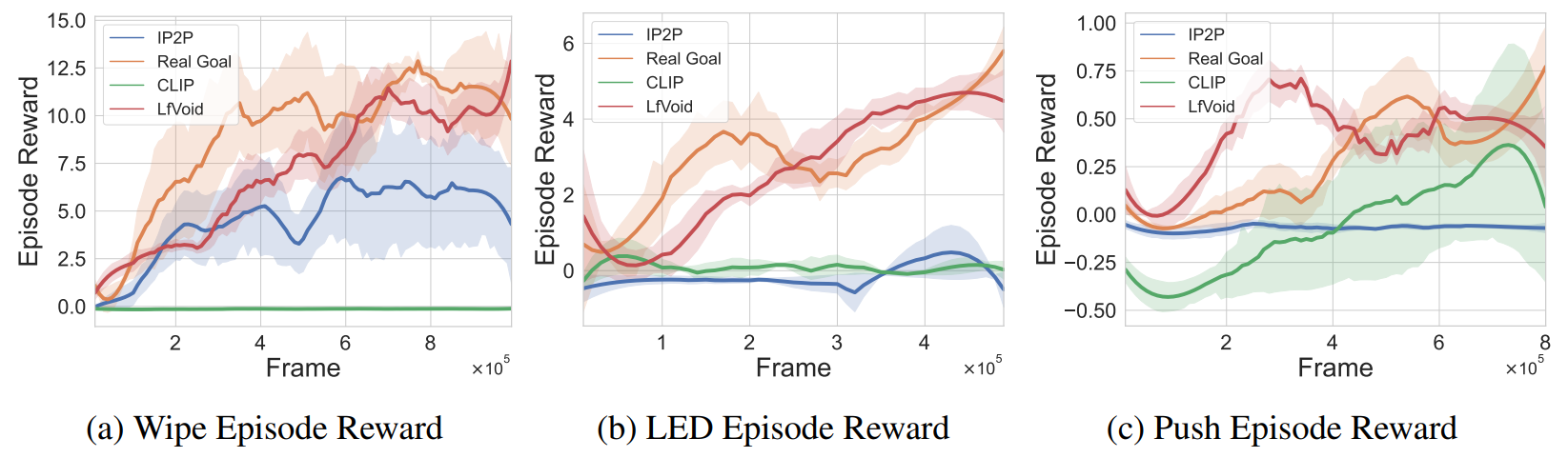
The episode reward curve of simulation tasks. We show the results of the CLIP baseline (CLIP), InstructPix2Pix baseline (IP2P), using real goal image as an upper bound (Real Goal), and LfVoid (Ours).

The numerical metrics of simulation tasks. We report the success rate for LED and Push, and the number of stain patches cleaned for Wipe.
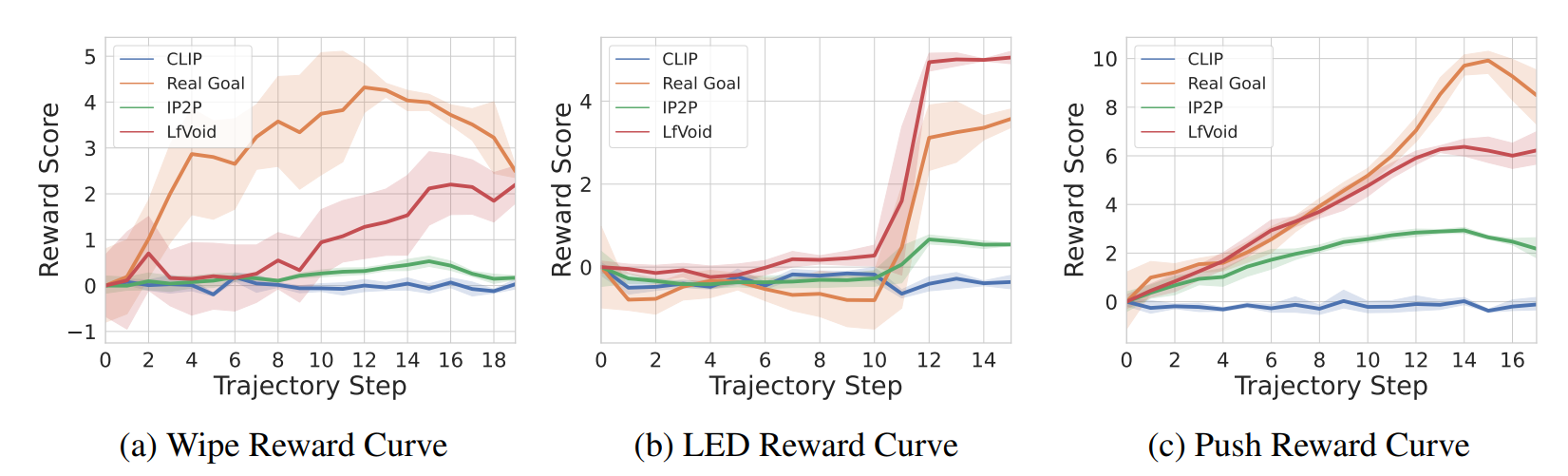
Visualization of the reward function on Real Robot environments. We visualize the classifier-based reward function obtained by the goal images generated through LfVoid (Ours) and other baselines on successful trajectories. Results show that the reward function obtained by LfVoid can provide near monotonic dense signals, comparable to those from the real goals.

Push Success |

Push Failure |
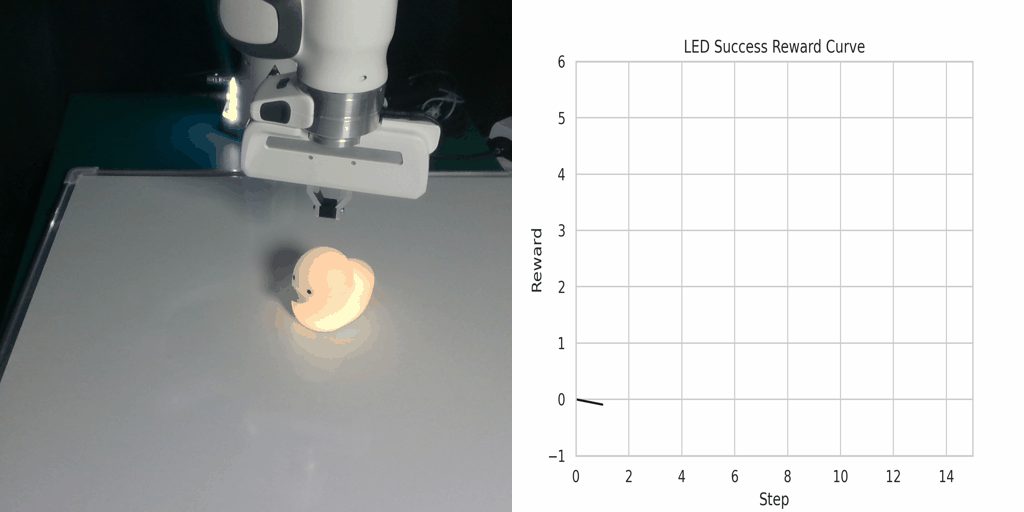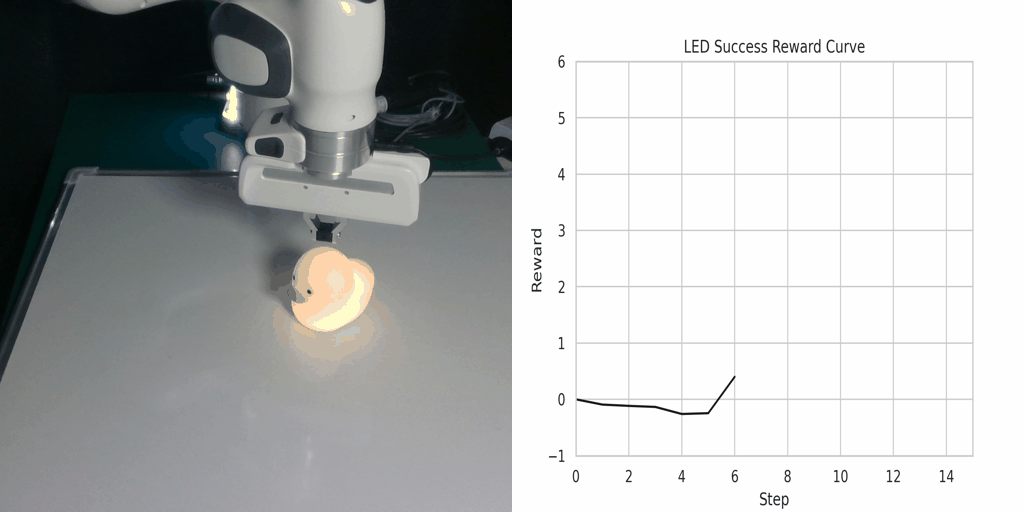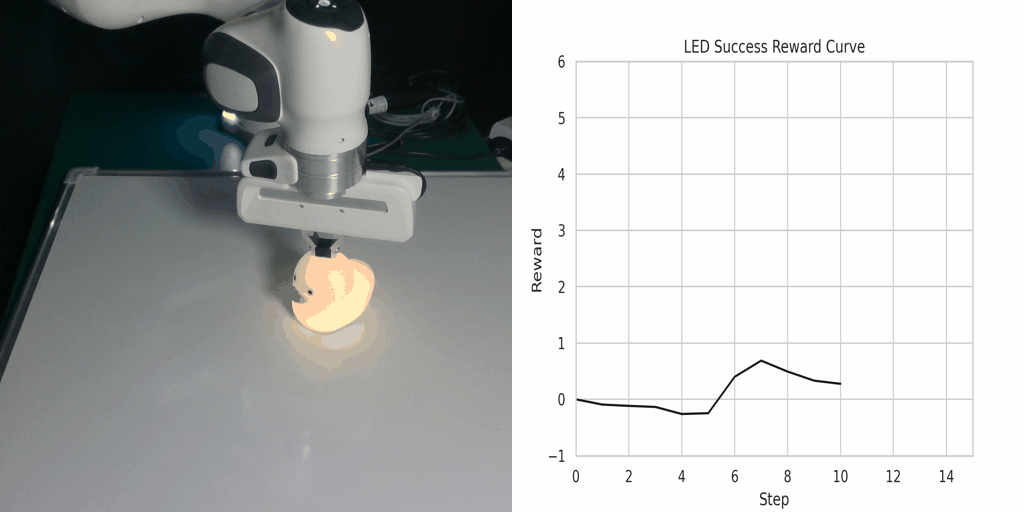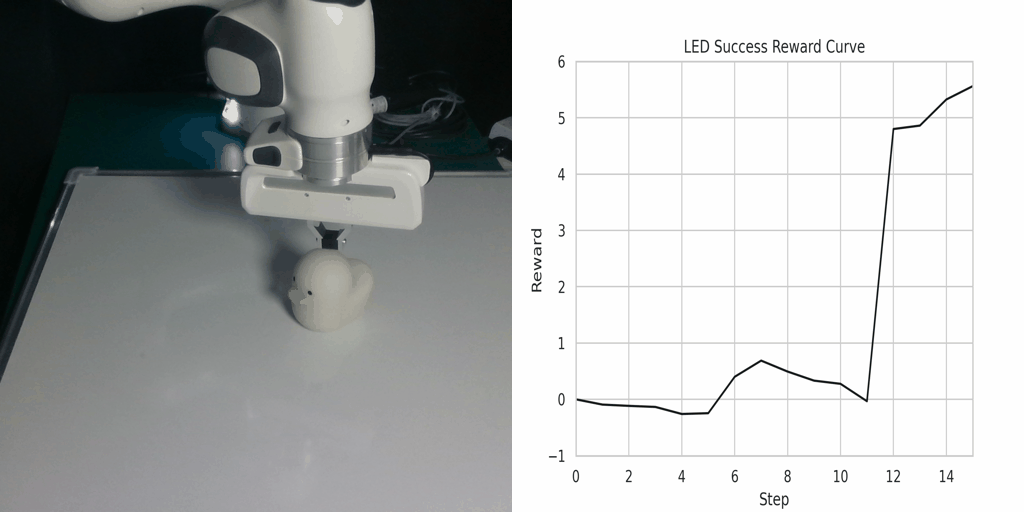
LED Success |

LED Failure |

Wipe Success |
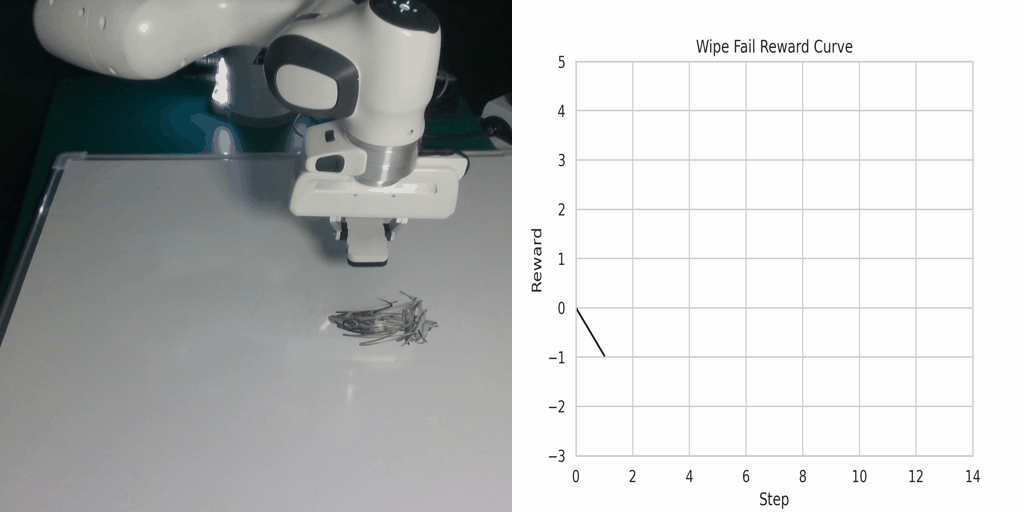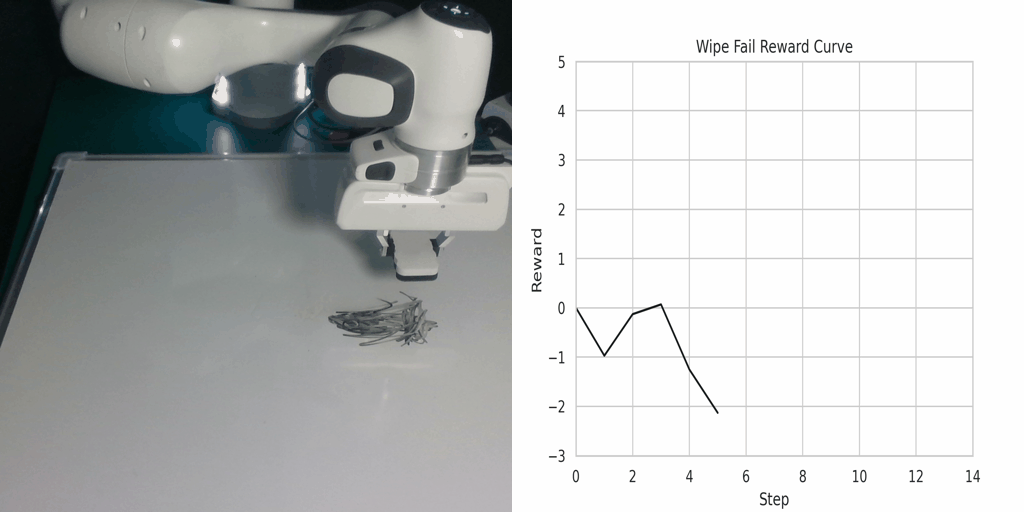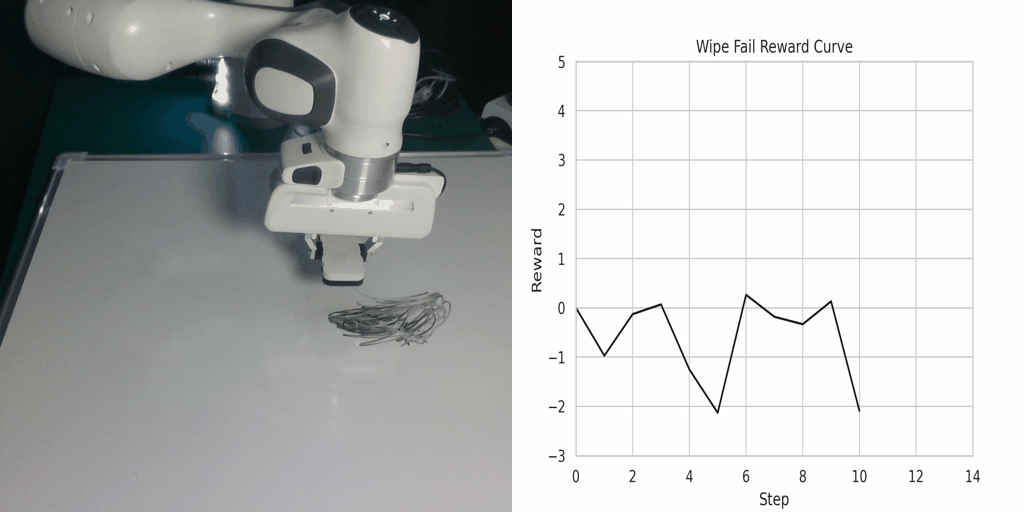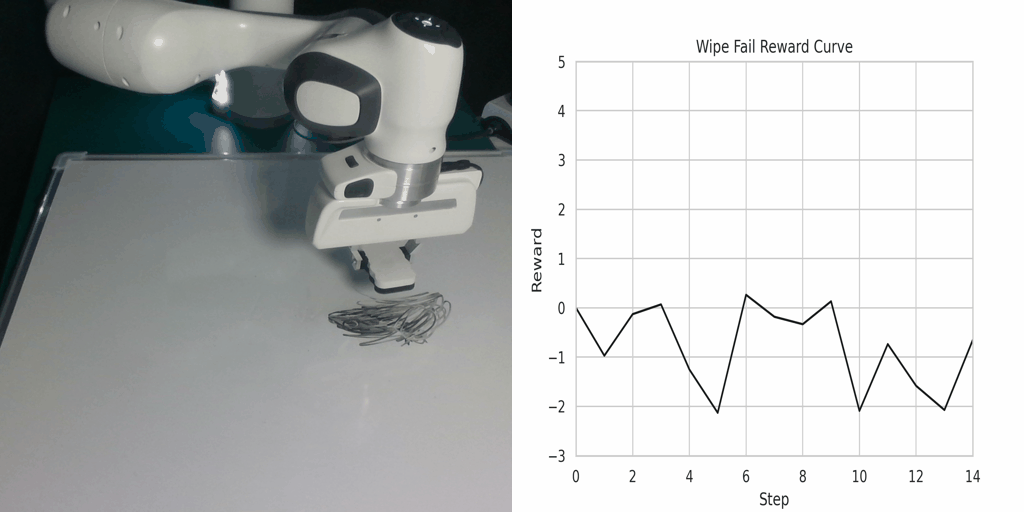
Wipe Failure |
Additionally, we provide some visualization videos of the classifier-based reward functions obtained by LfVoid on several successful and failed trajectories. We can observe that our reward function can assign monotonic increasing values for the successful demonstrations, while for failure trajectories the reward curve is almost flat. These visualizations further demonstrate LfVoid's plausibility for real world robotic tasks.
@misc{gao2023pretrained,
title={Can Pre-Trained Text-to-Image Models Generate Visual Goals for Reinforcement Learning?},
author={Jialu Gao and Kaizhe Hu and Guowei Xu and Huazhe Xu},
year={2023},
eprint={2307.07837},
archivePrefix={arXiv},
primaryClass={cs.RO}
}
Website adapted from the following template.